Private LLM Cluster: Trillion-Parameter Models, Zero Cloud Dependency
Some customers can’t send data to OpenAI or Anthropic. We built a 4-node Mac Studio cluster
with Thunderbolt 5 RDMA that runs trillion-parameter models locally — 28 tok/s,
fully private, no data leaves the building.
4
Mac Studio nodes (M4 Ultra)
1 TB
Unified memory (pooled via RDMA)
28+
Tokens/second (Kimi K2 1T params)
0
Data sent to cloud (fully on-premise)
The Problem
Enterprise customers in finance, defense, healthcare, and legal sectors need LLM capabilities but
cannot send proprietary data to cloud APIs. Regulatory requirements, NDA constraints,
and security policies prohibit it. The alternatives — renting GPU clusters or buying Nvidia DGX
hardware — cost six figures and require specialized DevOps teams.
The specific challenges:
Data sovereignty — customer data must never leave the on-premise environment, not even to an EU data center
Model size vs. hardware — the best open-weight models (Kimi K2, DeepSeek V3, Qwen3 235B) require 500GB–1TB+ of memory that no single machine provides
Cost of Nvidia path — an H100 cluster with equivalent VRAM costs 5–10× more, needs water cooling, and draws kilowatts of power
Operational simplicity — the customer needs an inference endpoint, not a CUDA/Linux administration project
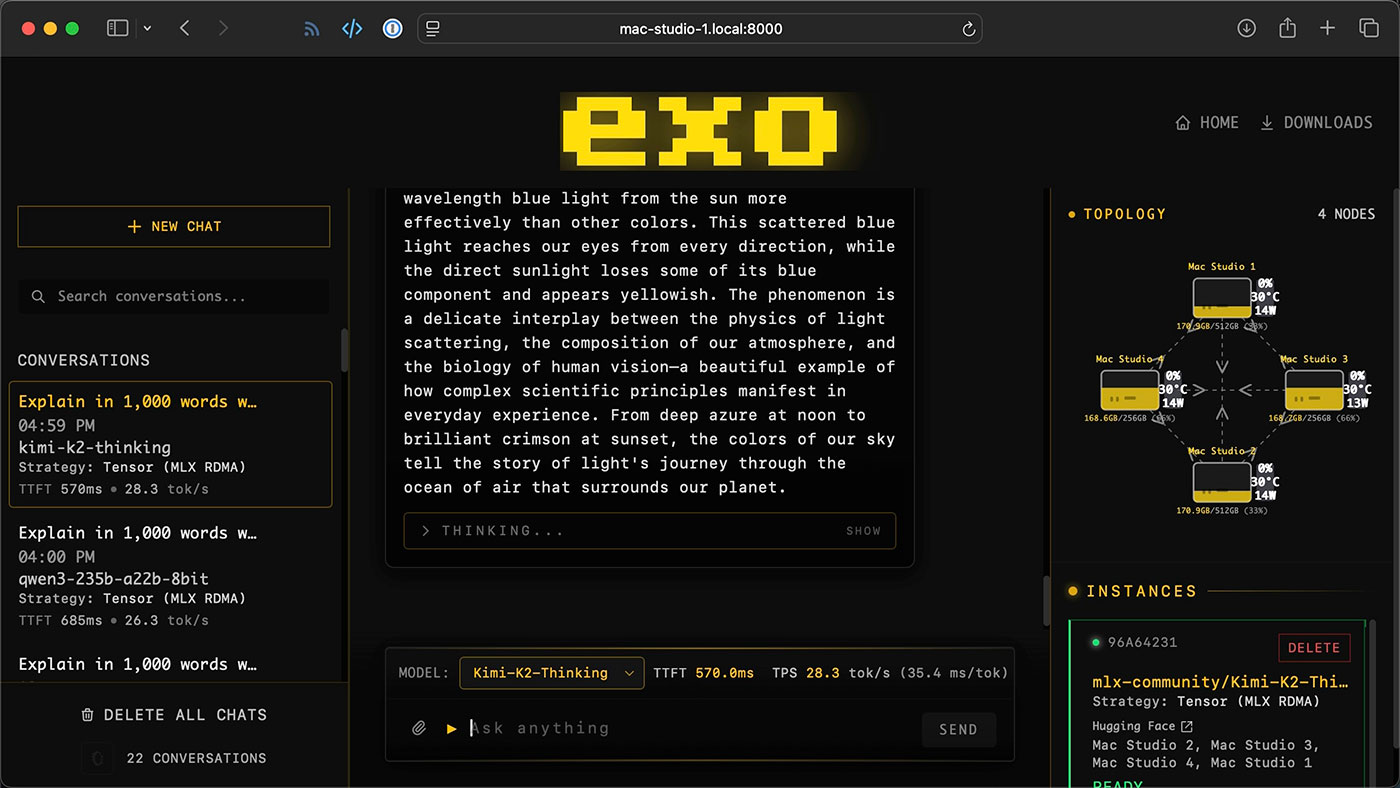
What We Built
A 4-node Mac Studio cluster using Apple M4 Ultra chips, interconnected via
Thunderbolt 5 with RDMA (Remote Direct Memory Access) enabled. The cluster pools 1 TB
of unified memory across nodes, allowing it to load and run models that no single machine could handle.
Hardware topology
4× Mac Studio M4 Ultra (256 GB) — inference nodes with tensor sharding
10 GbE Ethernet — management network and fallback path
Power draw — under 250W total for 4 nodes (idle <40W)
Distributed inference with EXO
We use EXO (open-source, Apache 2.0) for distributed inference orchestration.
EXO splits model layers across nodes using tensor parallelism over MLX RDMA — each Mac Studio
holds a shard of the model in its unified memory, and inference requests flow through the cluster
transparently.
Tensor strategy (MLX RDMA) — model weights are split across nodes at the tensor level, enabling true parallel computation
Automatic topology discovery — EXO detects all nodes and their available memory, assigns shards accordingly
OpenAI-compatible API — drop-in replacement for any application using the OpenAI SDK
Web UI — built-in chat interface with real-time monitoring of node utilization, temperature, and throughput
Models in production
The cluster runs multiple large open-weight models depending on customer needs:
MiniMax 2.5 — primary production model for customer-facing inference workloads
Kimi K2 Thinking (1T params) — 28.3 tok/s, TTFT 570ms — reasoning-heavy tasks and complex analysis
The decision comes down to memory density per dollar and operational simplicity.
Apple’s unified memory architecture means the GPU and CPU share the same memory pool —
256 GB of unified memory on a single Mac Studio is usable VRAM, not system RAM that needs
to be copied to a separate GPU.
Cost — 1 TB of usable VRAM for ~$30K vs. $200K+ for equivalent Nvidia H100 setup
Power — 250W for 4 nodes vs. 2,800W+ for 4× H100 GPUs alone (not counting host systems and cooling)
Noise — Mac Studios are silent, can sit in an office. No server room or water cooling required
Maintenance — macOS updates, no CUDA driver debugging, no Linux kernel compatibility issues
The tradeoff is raw throughput — Nvidia GPUs are faster for training and high-concurrency inference.
But for single-tenant private inference where the bottleneck is memory capacity (fitting the model),
not FLOPS, the Mac Studio cluster wins on total cost of ownership.
Standard TCP networking adds 300µs+ latency per hop — unacceptable when tensor shards need to
synchronize thousands of times per inference pass. Thunderbolt 5 RDMA reduces this to under 50µs by
bypassing the OS network stack entirely. Memory on node A is directly readable by node B as if it were local.
Enabling RDMA on macOS requires booting into recovery mode and running rdma_ctl enable on each node.
The mesh topology connects all 4 nodes directly — no switch needed (Thunderbolt 5 switches don’t
exist yet).
Tensor parallelism with MLX
Apple’s MLX framework is optimized for Apple Silicon’s unified memory architecture.
Unlike PyTorch or TensorFlow, MLX avoids unnecessary memory copies between CPU and GPU because they share the same
physical memory. Combined with EXO’s tensor sharding, a 1-trillion-parameter model is split across 4 nodes
at the weight matrix level, with each node computing its portion and exchanging activations via RDMA.
Deployment and operations
Model loading — download HuggingFace model once, EXO distributes shards to nodes automatically
API endpoint — standard OpenAI-compatible HTTP endpoint, works with any client library
Monitoring — EXO web UI shows per-node GPU utilization, temperature, memory usage, and throughput in real time
Model switching — swap models in minutes, no recompilation or container rebuilds needed
Results
28.3 tok/s on Kimi K2 Thinking (1 trillion parameters) — conversational speed for complex reasoning
26.3 tok/s on Qwen3 235B (8-bit) — fast multilingual inference
570ms TTFT — time to first token, comparable to cloud API latency
Zero data exfiltration risk — models and data stay on-premise, air-gappable if needed
~5× cheaper than equivalent Nvidia GPU cluster for memory-bound workloads
Office-friendly — silent operation, standard power outlet, no server room required
Key Takeaway
The assumption that running large language models requires expensive Nvidia GPU clusters is outdated.
Apple Silicon’s unified memory architecture, combined with Thunderbolt 5 RDMA and open-source
distributed inference tools, makes it possible to run trillion-parameter models privately for a fraction
of the cost.
For customers who need LLM capabilities but can’t — or won’t — send data to the cloud,
this is no longer a compromise. It’s a competitive advantage: the same model quality,
the same API interface, with absolute data control.
Need a Private LLM Infrastructure?
We design and deploy on-premise LLM clusters for enterprises that need AI without cloud dependency. Let’s discuss your requirements.