PŘÍPADOVÁ STUDIE · AI INFRASTRUKTURA · PRIVÁTNÍ LLM
Privátní LLM cluster: Bilionové modely, nulová závislost na cloudu
Někteří zákazníci nemohou posílat data do OpenAI nebo Anthropic. Postavili jsme 4-uzlový
Mac Studio cluster s Thunderbolt 5 RDMA, který provozuje bilionové modely lokálně —
28 tok/s, plně privátně, žádná data neopouštějí budovu.
4
Mac Studio uzly (M4 Ultra)
1 TB
Sdílená paměť (poolovaná přes RDMA)
28+
Tokenů/sekundu (Kimi K2, 1T parametrů)
0
Data odeslaná do cloudu (plně on-premise)
Problém
Podnikoví zákazníci ve financích, obraně, zdravotnictví a právních službách potřebují schopnosti LLM,
ale nemohou posílat proprietární data do cloudových API. Regulatorní požadavky, omezení
NDA a bezpečnostní politiky to zakazují. Alternativy — pronájem GPU clusterů nebo nákup Nvidia DGX
hardwaru — stojí stovky tisíc a vyžadují specializované DevOps týmy.
Konkrétní výzvy:
Datová suverenita — zákaznická data nesmí nikdy opustit on-premise prostředí, ani do EU datového centra
Velikost modelu vs. hardware — nejlepší open-weight modely (Kimi K2, DeepSeek V3, Qwen3 235B) vyžadují 500 GB–1 TB+ paměti, kterou žádný jednotlivý stroj nenabízí
Cena Nvidia cesty — H100 cluster s ekvivalentní VRAM stojí 5–10× více, potřebuje vodní chlazení a spotřebovává kilowatty
Provozní jednoduchost — zákazník potřebuje inferenční endpoint, ne CUDA/Linux administrační projekt
Co jsme postavili
4-uzlový Mac Studio cluster s čipy Apple M4 Ultra, propojený přes
Thunderbolt 5 s povoleným RDMA (Remote Direct Memory Access). Cluster sdílí 1 TB
unifikované paměti napříč uzly, což umožňuje načítat a provozovat modely, které by žádný
jednotlivý stroj nezvládl.
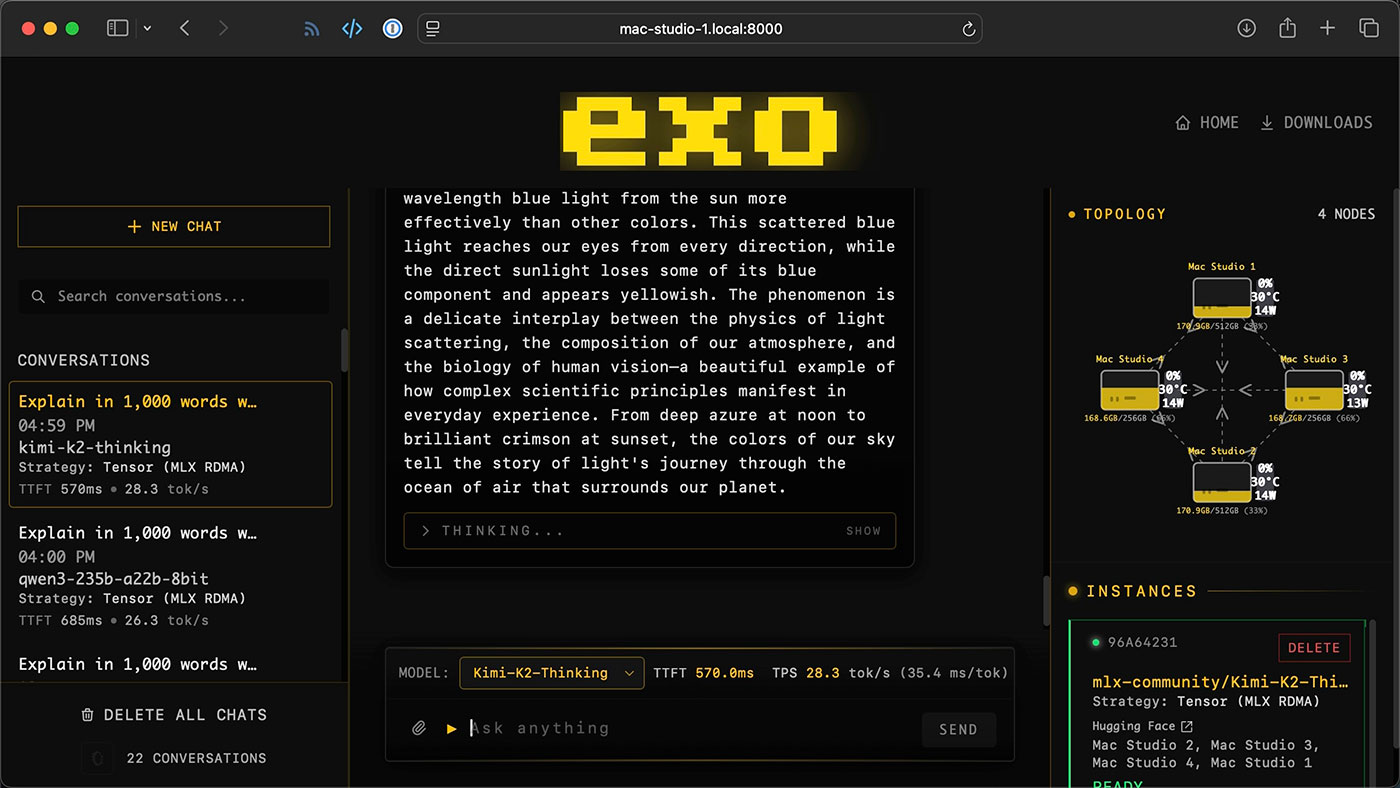
Hardwarová topologie
4× Mac Studio M4 Ultra (256 GB) — inferenční uzly s tensor shardingem
Spotřeba — pod 250 W celkem pro 4 uzly (idle <40 W)
Distribuovaná inference s EXO
Používáme EXO (open-source, Apache 2.0) pro orchestraci distribuované inference.
EXO rozděluje vrstvy modelu napříč uzly pomocí tensor paralelismu přes MLX RDMA — každé
Mac Studio drží fragment modelu v unifikované paměti a inferenční požadavky procházejí clusterem
transparentně.
Tensor strategie (MLX RDMA) — váhy modelu jsou rozděleny na úrovni tenzorů, což umožňuje skutečný paralelní výpočet
Automatické rozpoznání topologie — EXO detekuje všechny uzly a jejich dostupnou paměť, přiřazuje fragmenty automaticky
OpenAI-kompatibilní API — drop-in náhrada pro jakoukoli aplikaci používající OpenAI SDK
Webové rozhraní — vestavěný chat s monitoringem vytížení uzlů, teploty a propustnosti v reálném čase
Modely v produkci
Cluster provozuje několik velkých open-weight modelů podle potřeb zákazníků:
MiniMax 2.5 — primární produkční model pro zákaznické inferenční úlohy
Kimi K2 Thinking (1T parametrů) — 28,3 tok/s, TTFT 570 ms — úlohy náročné na uvažování a komplexní analýzy
Qwen3 235B (8-bit) — 26,3 tok/s, TTFT 685 ms — vícejazyčné úlohy, kódování a obecná inference
Architektura clusteru
4× Mac Studio
M4 Ultra · 1 TB
Thunderbolt 5
RDMA · <50µs
EXO + MLX
Tensor paralelismus
OpenAI API
Drop-in kompatibilní
100% on-premise
Bilionové modely
<250 W celková spotřeba
Proč Mac Studio, ne Nvidia?
Rozhodnutí se odvíjí od hustoty paměti na dolar a provozní jednoduchosti.
Architektura unifikované paměti Apple znamená, že GPU a CPU sdílejí stejný fond paměti —
256 GB unifikované paměti na jednom Mac Studiu je využitelná VRAM, ne systémová RAM,
kterou je třeba kopírovat na oddělenou GPU.
Cena — 1 TB využitelné VRAM za ~$30K oproti $200K+ za ekvivalentní Nvidia H100 sestavu
Spotřeba — 250 W pro 4 uzly oproti 2 800 W+ pro 4× H100 GPU samotné (bez hostitelských systémů a chlazení)
Hluk — Mac Studia jsou tichá, mohou stát v kanceláři. Žádná serverovna ani vodní chlazení
Údržba — aktualizace macOS, žádné ladění CUDA ovladačů, žádné problémy s kompatibilitou Linux jádra
Kompromis je surový výkon — Nvidia GPU jsou rychlejší pro trénování a inference s vysokou souběžností.
Ale pro jednotenantní privátní inferenci, kde je úzkým hrdlem kapacita paměti (vejít se s modelem),
nikoli FLOPS, Mac Studio cluster vyhrává na celkových nákladech na vlastnictví.
Standardní TCP síťování přidává 300µs+ latenci na hop — nepřijatelné, když se tensor fragmenty
potřebují synchronizovat tisíckrát za jeden inferenční průchod. Thunderbolt 5 RDMA to snižuje
pod 50µs obcházením OS síťového stacku. Paměť uzlu A je přímo čitelná uzlem B,
jako by byla lokální.
Povolení RDMA na macOS vyžaduje nabootování do recovery módu a spuštění rdma_ctl enable
na každém uzlu. Mesh topologie propojuje všechny 4 uzly přímo — žádný switch není potřeba
(Thunderbolt 5 switche zatím neexistují).
Tensor paralelismus s MLX
Framework MLX od Apple je optimalizovaný pro architekturu unifikované paměti Apple Silicon.
Na rozdíl od PyTorch nebo TensorFlow se MLX vyhýbá zbytečným kopiím paměti mezi CPU a GPU, protože sdílejí
stejnou fyzickou paměť. V kombinaci s tensor shardingem EXO je bilionový model rozdělen napříč 4 uzly
na úrovni váhových matic, přičemž každý uzel počítá svoji část a vyměňuje si aktivace přes RDMA.
Nasazení a provoz
Načtení modelu — stáhnutí z HuggingFace jednou, EXO distribuuje fragmenty na uzly automaticky
API endpoint — standardní OpenAI-kompatibilní HTTP endpoint, funguje s jakoukoli klientskou knihovnou
Monitoring — webové rozhraní EXO zobrazuje vytížení GPU, teplotu, spotřebu paměti a propustnost v reálném čase
Přepínání modelů — výměna modelu během minut, žádná rekompilace ani přestavba kontejnerů
Výsledky
28,3 tok/s na Kimi K2 Thinking (1 bilion parametrů) — konverzační rychlost pro komplexní uvažování
26,3 tok/s na Qwen3 235B (8-bit) — rychlá vícejazyčná inference
570 ms TTFT — čas do prvního tokenu, srovnatelný s latencí cloudových API
Nulové riziko úniku dat — modely i data zůstávají on-premise, v případě potřeby i air-gap
~5× levnější než ekvivalentní Nvidia GPU cluster pro paměťově omezené úlohy
Vhodný do kanceláře — tichý provoz, standardní zásuvka, žádná serverovna
Klíčové zjištění
Předpoklad, že provozování velkých jazykových modelů vyžaduje drahé Nvidia GPU clustery, je překonaný.
Architektura unifikované paměti Apple Silicon v kombinaci s Thunderbolt 5 RDMA a open-source
nástroji pro distribuovanou inferenci umožňuje provozovat bilionové modely privátně za zlomek nákladů.
Pro zákazníky, kteří potřebují schopnosti LLM, ale nemohou — nebo nechtějí — posílat data
do cloudu, to již není kompromis. Je to konkurenční výhoda: stejná kvalita modelu,
stejné API rozhraní, s absolutní kontrolou nad daty.
Potřebujete privátní LLM infrastrukturu?
Navrhujeme a nasazujeme on-premise LLM clustery pro podniky, které potřebují AI bez závislosti na cloudu. Prodiskutujme vaše požadavky.